

| ‘AI saves eCommerce professionals an average of 6.4 hours per week.’ —- Salesforce |
That productivity gain explains why AI is moving quickly into catalog management, from attribute extraction and taxonomy mapping to duplicate detection to content generation.
But higher output does not automatically mean better catalog data. AI models introduce errors through misread attributes, incorrect categories, unsupported product claims, or flawed variant relationships. Once those errors enter a high-volume catalog pipeline, they compound across SKUs, variants, and channel feeds.
The Right Approach: Leveraging AI for scalability with specialist validation for accuracy.
The Bottlenecks: Where eCommerce Catalog Management Breaks at Scale
1. Inconsistent Supplier Data
Product data is ingested from hundreds of supplier and vendor feeds, each with its own format, naming convention, and categorization scheme. Each new source requires schema mapping and attribute normalization before its records are catalog-ready. At scale, onboarding becomes the primary data bottleneck because the integration effort grows with each additional supplier.
2. Data Quality and Taxonomy
As the catalog expands, maintaining a consistent taxonomy across every product becomes harder. Inconsistent attribute values fragment that taxonomy. For instance, when a single color is recorded as “red,” “crimson,” and “scarlet” across the catalog, one filter value splits into three.
3. Variant and Bundle Complexity
A single product expands into parent-child variants across size, color, and specification, while bundles group multiple products into a single unit whose price and stock depend on every component. Every variant requires its own complete attribute set, so completeness must hold across a record count that multiplies with each added dimension. Pricing or inventory changes must propagate correctly through all linked variants and bundles. At scale, these interdependencies make bulk updates and dynamic pricing rules increasingly error-prone.
4. Digital Asset Management
Each product includes visual assets alongside its data, such as high-resolution images, videos, and 3D models. Every channel imposes its own size, format, and aspect-ratio requirements for those assets. Maintaining a correct, channel-ready asset set for every SKU adds a parallel production workload that scales with the catalog.
5. Multi-Channel Synchronization
Pricing, inventory, and product content must remain accurate and up to date across all active channels simultaneously, including owned storefronts, marketplaces, and social commerce platforms. Synchronizing that data is technically complex because each channel requires its own format and update frequency, and those requirements change over time. A pricing error or an out-of-sync inventory count surfaces immediately on the storefront, suppressing conversions and eroding buyer trust.
How AI in Catalog Management Scales Operations
1. Product Data Enrichment and Attribute Extraction
AI models extract structured attributes from supplier catalogs, specification PDFs, and unstructured product descriptions, then normalize them into consistent values, units, and naming conventions. This covers the full attribute-extraction workflow, from raw supplier data ingestion to standardized, channel-ready product records, at the throughput required by enterprise catalog volumes.
2. Product Data Classification and Taxonomy Mapping
Classification models can help map products to the correct category in each channel’s taxonomy by training on existing catalog data to learn product-to-category relationships, enabling the system to classify new product feeds as they are ingested. For unstructured inputs such as product titles, descriptions, and supplier notes, the models first parse the raw text to extract features, brands, and materials before applying classification.
This covers taxonomy mapping across Amazon browse nodes, Walmart product hierarchies, Google Product Categories, and structured classification frameworks such as UNSPSC and ECLASS, while maintaining classification accuracy across all active channels as catalog volume grows.
3. Duplicate SKU Detection and Data Deduplication
AI compares records semantically, evaluating descriptions, specifications, and supplier data together to surface SKUs that represent the same product data ingested through different supplier feeds. This extends beyond exact-match deduplication to capture records in which a single unit variant, abbreviation, or formatting difference separates two identical products.
For instance, a product entered as “M8 x 1.25 Hex Bolt, Stainless Steel, 30mm” from one supplier and “SS Hex Bolt M8 30mm 1.25 Pitch” from another will not be caught by exact-match deduplication. Semantic matching identifies both records as the same product and flags them for a specialist review.
4. Bulk Product Content Generation
Generative models produce SEO-optimized product titles, feature bullet points, and descriptions from structured attribute data such as specifications, dimensions, materials, and category fields. AI models adapt each output to each channel’s format and character limits, holding tone and structure consistent across the catalog.
Where AI Produces Errors in Catalog Operations
| ‘The importance of data quality in AI cannot be overstated: poor data quality is one of the most common reasons AI initiatives fail. AI models trained on flawed, biased or incomplete data will produce unreliable outputs regardless of how sophisticated architectures might be. As the saying goes: garbage in, garbage out.’ —IBM |
AI handles catalog operations at volume, but doesn’t guarantee accuracy. Some errors trace to flawed input data, the kind IBM describes; others trace to the model’s own misreads and hallucinations.
1. Attribute Extraction and Generation
When extracting attributes from vendor feeds and PDFs, the model may misread or omit values. For instance, it may read inches as centimeters, or miss a specification stated only in prose. When a required field is missing, the model may populate it based on pattern recognition rather than the source data. For instance, it may assign a material, dimension, or compatibility value that the source never confirmed.
In both cases, the inaccurate or missing attribute reaches the live listing unless it is validated against source data. A fabricated value misrepresents the product and drives returns, while a missing or misread attribute drops it from filtered and natural-language search.
2. Variant Mapping and Grouping
A product’s size, color, and bundle options are variants that should roll up under one parent listing. AI often reads them as separate products instead, fragmenting the variant family. The fragments then carry inconsistent data on the storefront.
For instance, search may show the wrong image, pull pricing from a discontinued variant, or split one inventory count across several listings.
3. Product Matching and Deduplication
Deduplication should merge records describing the same product while keeping distinct products separate. It fails in two directions.
- During semantic matching, the model can merge two distinct products that share the same titles and descriptions but differ in a critical attribute. For instance, the model matches the two products on description and merges them, though a feature, certification, or compatibility rating sets them apart.
- It can also miss true duplicates when minor differences separate the same product across feeds. For instance, a typo or a missing field.
4. Categorization and Taxonomy
Categorization assigns each product to a node in the channel’s category tree based on its title, description, and attributes. AI miscategorizes when a legacy ERP or PIM structure does not match the target taxonomy, so the model guesses the mapping and misplaces it.
It also fails when the correct category depends on a context that the product data does not capture. For instance, an industrial fastener’s category may hinge on its application, which the title omits, so the model classifies it by surface keywords. Miscategorized products then drop out of category navigation and filters.
5. Brand and Regulated Compliance
AI-generated copy can meet grammar and SEO standards while ignoring the rules that govern the listing. Those rules include brand guidelines, approved claim language, and channel-specific positioning. In regulated categories, such as medical devices, cosmetics, and children’s care, a model trained on prior policy can generate content that current rules reject.
Once live, such content can trigger content takedowns, listing suppression, marketplace penalties, and regulatory exposure.
AI Operational Debt: High-Volume Error Propagation Without a Validation Layer
AI-powered catalog management increases throughput, but without validation, it scales errors at the same rate. A flawed enrichment rule, an incorrect attribute mapping, or a systematic model error does not remain confined to a single record. It replicates across every SKU, category, and variant family that the system processes, and each automated cycle compounds it further. A single flaw becomes a catalog-wide defect.
When product data quality breaks down, the effects compound across discovery, conversion, and retention:
- Incomplete or inconsistent attributes break filtering and navigation, so in-stock products lose discoverability across on-site and marketplace search.
- Vague or incomplete product details lower shopper confidence and increase cart abandonment at the point of decision.
- Marketplaces trigger listing suppression or suspension when listings fail compliance checks, such as GTIN and UPC errors, missing attributes, wrong categories, or image non-compliance.
- Listings that misrepresent the delivered product drive returns, which add reverse-logistics cost and lower product rankings on return-sensitive marketplaces.
- Recommendation and personalization engines surface irrelevant products that do not reflect shopper intent, reducing conversion rates on cross-sell and upsell opportunities.
- AI assistants and shopping agents evaluate products from structured, machine-readable attributes, so listings without that data are excluded from their results entirely.
- Repeated inconsistencies between listing content and the actual products erode brand trust, reducing repeat purchase rate and customer lifetime value.
The Human-in-the-Loop (HITL) Operating Model for Catalog Management
In McKinsey’s 2025 State of AI survey, the organizations getting real value from AI shared one practice above all: a defined human-in-the-loop process. They adopted it at nearly three times the rate of everyone else, 65% versus 23%.
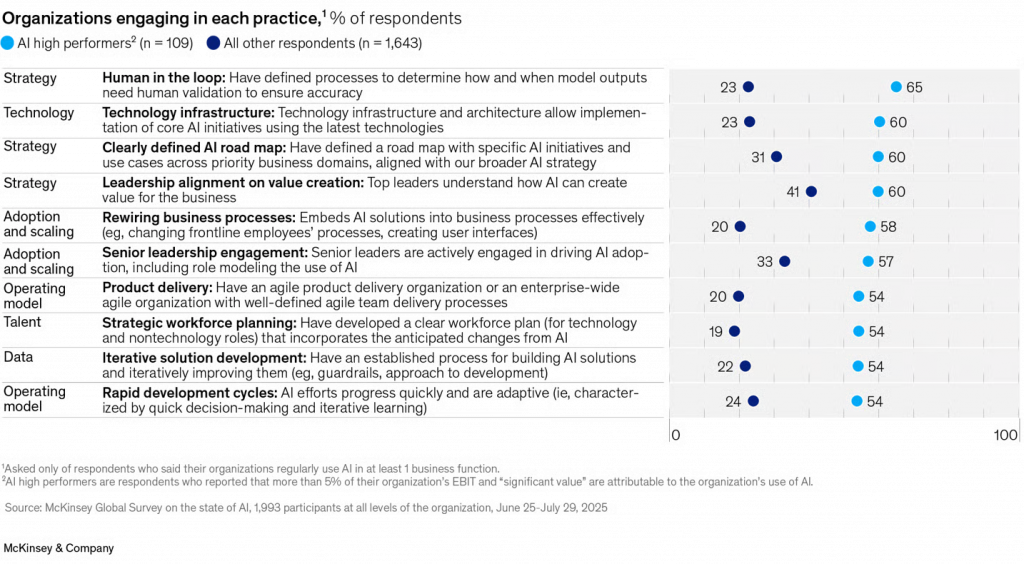
[Source: McKinsey| State of AI in 2025 Report]
The stages below translate that practice into a framework for catalog management.
Stage 1: Automated Catalog Processing and Triage
What AI handles:
- Attribute extraction from supplier feeds, PDFs, and manufacturer websites
- Attribute normalization and data standardization across units, naming conventions, and formats
- Taxonomy classification against each channel’s required category structure
- Duplicate SKU detection across the full catalog using semantic matching
- Bulk product content generation from structured attribute data
- Confidence scoring for each output based on data completeness and match certainty
- Risk flagging for regulated categories, proposed SKU merges, and low-confidence specifications
Routing Outcome: High-confidence, low-risk records go live automatically across all channels, without specialist review. Automation handles this volume, leaving specialists to focus only on the exceptions.
Stage 2: Specialist Exception Review
Records that fail confidence thresholds or match risk criteria route to a structured specialist queue. Each record arrives with a rationale for flagging attached.
What the specialist handles:
| Decision Type | Role of Manual Intervention |
| Merge interchangeability review | Cross-references proposed SKU merges against source documentation to verify that merged records describe functionally identical products |
| Regulated category compliance | Reviews AI-generated content for claim language, required safety statements, and current marketplace policy compliance before approving regulated SKUs for syndication |
| Brand guideline enforcement | Validates product descriptions against approved claim language, feature hierarchy guidelines, and channel-specific positioning rules |
| Complex taxonomy decisions | Resolves classification edge cases where a product spans multiple category structures or where the channel taxonomy has been recently updated |
| Low-confidence specification review | Verifies AI-generated or AI-inferred specifications against manufacturer documentation or verified supplier data before the record goes live |
Routing Outcome: After review, verified records go live across every channel. Records that still contain errors are returned to the automated pipeline, along with structured correction signals specifying which fields require correction and why.
Stage 3: Feedback Loop and Model Refinement
Each validated specialist correction becomes labeled training data for the next retraining cycle. Over time, this feedback loop improves confidence scoring, taxonomy alignment, and attribute extraction. As the model learns from reviewed outcomes, fewer records require manual escalation, reducing exception volume and lowering cost per record.
The SAMM Data case study below establishes what this model delivers at scale.
| For a luxury lighting retailer managing product data from more than 120 brands, SAMM Data combined automation with specialist validation. Their team standardized 90+ product fields, mapped parent-child variants, and applied multi-level quality checks before upload.
The Result: A controlled catalog management workflow with
The case reinforces the core HITL principle: automation offers scale, but specialist validation delivers accurate, complete output. |
The Next Step: Governed AI Catalog Operations
For eCommerce retailers and distributors, the next step is to establish an operating model with defined automation workflows, specialist review for exception cases, and structured feedback loops to improve future output.
Where to Begin? Start with the operations where errors create the highest downstream impact: supplier onboarding, taxonomy mapping, variant grouping, attribute enrichment, pricing, inventory, compliance, and marketplace syndication. Determine which operations can be automated, which require validation, and which corrections must be captured for model, rule, and process refinement.
This framework would enable teams to deploy AI in operations at scale without compromising output accuracy.
Author Bio:
Eliana Wilson is an experienced eCommerce consultant at Data4eCom, a leading outsourcing agency providing end-to-end eCommerce services, with a strong background in multi-channel selling, digital marketing, and product data management. She works closely with brands and online retailers to streamline operations, enhance visibility, and scale revenue across platforms, such as Amazon, Walmart, and eBay. Her expertise spans product listing optimization, marketplace compliance, eCommerce PPC, and catalog management. Eliana regularly shares insights to help businesses overcome growth challenges and stay competitive.



{kind=link}