

The term, ‘Data Lake’ came into being due to James Dixon, the appointed Chief Technology Officer and one of the founders of Pentaho during the year 2010. A data lake can be defined as a data repository that stores data in its format of origin or in its raw format. A data lake can store various types of data, including structured data, semi-structured data, unstructured data and binary data as well. This translates to it being capable of storing multiple file formats such as CSV, XML, PDFs, images, video and the list goes on. A well-orchestrated Data Science course can help you delve deeper into this concept of data lakes that organizations like Google, Oracle, Amazon, and MongoDB are offering.
Definition of Data Lake
Simply put, a data lake is a type of architecture that holds vast amounts of data in raw or native formats till the time it is required. As compared to Data Silos, data lakes function much more efficiently and effectively. PricewaterhouseCoopers or better known as PWC has also been reported to predict that data lakes will soon replace data silos. Also, as compared to data houses, data lakes use a flat architectural design for storing data. PWC has also mentioned that many organizations are beginning to use singular data repositories which are based on Hadoop.
A data lake is generally a singular data storage that contains raw or native copies of the source system and sensor data or transformed data which can be later utilized for visualizing, reporting, running advanced analytical processes and for machine learning. Due to being dependent on Hadoop, data lakes can also be configured to run on clusters of cheaper basic hardware which also contributes to increased scalability. This is making data dumping in data lakes a common occurrence for organizations to remove worries about on-premise or internal storage capacities. In the case of data lakes, the clusters can be run from the cloud or on-premise.
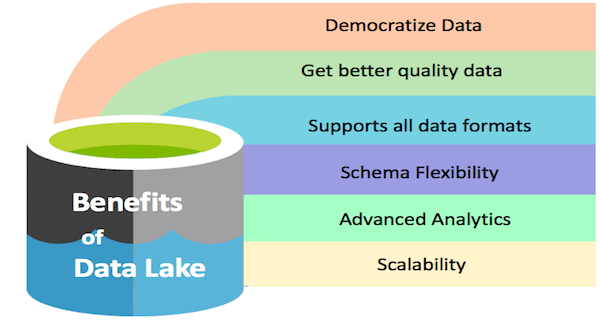
Benefits of Data Lake
The main benefit of data lakes that we can all agree upon is that any type of data can be stored in a single storage location which decreases the expenses of corporations. Organizations can gain valuable insights rapidly and at any given time from all this data available for use. Here are a few other benefits of using data lakes.
1. Higher Quality of Data
Data lakes provide enormous processing power which makes sure that the quality of the data is not compromised.
2. Adaptability and Schema Flexibility
Data lakes eliminate the requirement to model data during the process of ingestion. Data Modelling is done during finding and exploring data for the purpose of analytics and gaining insights. It is also highly scalable and comparably a cheaper alternative than other solutions like data warehouses. It is also highly versatile and is capable of storing multi-structured data from various sources.
3. Support for Multiple Languages
Data lakes support various languages, unlike other data storage solutions. Data lakes not only support SQL but also PIG and Spark MLib for advanced data analytics and machine learning. An expansive data science course is highly recommended to learn the languages required to effectively use multiple tools to utilize data lakes.
4. Promotes Advanced Analysis and Analytics
Data lakes excel at using the available quantities of big data which is stored inside its architecture with the help of deep learning and machine learning at a rapid pace which also contributes to live feedback and near live decision-making analytics.
How is it different from a Data Warehouse?
Data Warehouses were first introduced by Bill Inmon during the 1970s. This concept was developed with the sole intention of using centralized repositories of data to gain valuable insights which lead to more effective business decisions. Similar to data lakes, the data can come from various sources but are generally unstructured in kind. Data warehouses are mostly built upon the mainframe servers or in the cloud and utilize various tools and SQL clients to access the data. The main difference between data lakes and warehouses is the kind of data they store. Data lakes store native and raw data that is unprocessed. Meanwhile, data warehouses store processed and refined data instead. Data lakes turn into data swaps sometimes due to inappropriate data governance and bad quality of data. Data warehouses avoid this occurrence as it only stores quality data and also saves companies storage space by not maintaining unprocessed data which has a chance of never being utilized. Here are some more fundamental differences between data lakes and data warehouses.
- Data warehouses only store processed data and all the data is meant for individual purposes. Data lakes store all kinds of data that might never be used.
- Data lakes are harder to explore, especially for beginners with less experience of working with raw data types. A reputable data science course is highly useful in gaining the required knowledge to navigate around complex data structures. Data warehouses are much easier to navigate around with the data being processed.
- Data lake architectures are easier to access due to not having any defined structural limitations. Data lakes can be rapidly modified as compared to data warehouses. However, data warehouses are more secure due to being closed off and more matured in nature.
Data warehouses are more stable and structured in general and ease data deciphering due to the data being processed priorly. This limits data warehouses a bit due to not being able to store all kinds of data types and structures. This also makes data warehouses costly to manipulate and more expensive to maintain. Even though both are used to store data, their individual utilities cannot be interchanged or their necessity cannot be fulfilled by the other. Data lakes are massive pools of unprocessed data without their requirement being defined or known. Data lakes and data warehouses have more differences than similarities, with the only thing in common being the fundamental and common goal of high-level data storage. These differences must be identified and are quite important when deciding which system to use depending on the requirement.



{kind=link}